When importing authority files, a distinction must be made between two workflows: the first or original import (initial import) and the later imports (data synchronization), which also allow for modifications or deletions of previously imported entities. Below, the initial import is described, since its mechanism can also be used for data synchronization. However, depending on the type and amount of files, individual mechanisms in negotiation with the provider are preferable.
Initialimport
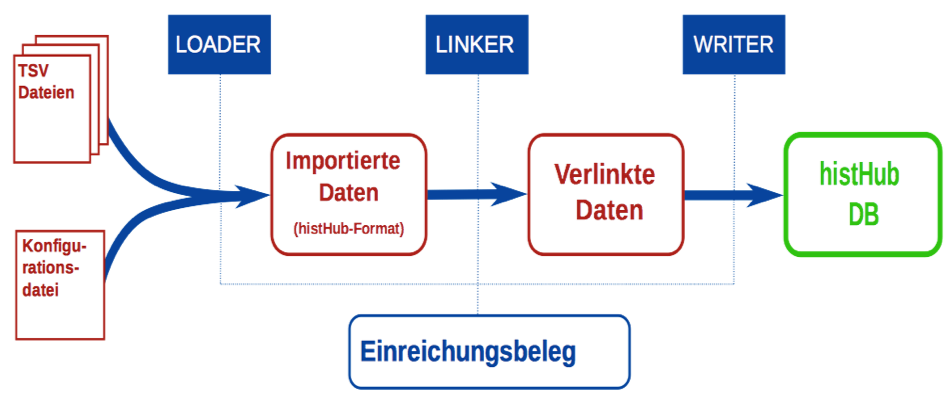
The initial import of authority files involves three simple steps:
- Load: With the support of histHub, the files of the provider are transformed into the histHub ontology (link). The input of the loader are so-called TSV files (TSV: tab-separated values) – tabular text files à la Excel – and a configuration file that specifies the mapping between provider files and histHub ontology.
- Link: In the linking process, concordances are searched between the files which are to be imported and the authority files which are available in the histHub database. Whether or not an entity which is to be imported (such as a person) already exists in the histHub-database will be checked. If the decision can not be made automatically (using machine learning methods), the provider must manually determine if there is a concordance, with the help of histHub. If the link has already been made via Metagrid, etc., the links in this step will be checked.
- Write: The new entities will receive a histHub ID (a fixed identifier). The existing entities will be enriched with the imported data. It may concern additional places of activity of a person.
The three steps are outlined in the graph below: