Während menschliche Nutzer durch ihr Welt- und Kontextwissen die Bedeutung von Daten und deren Zusammenhang selbst aus einer unstrukturierten Datenmenge meist noch erschliessen können, gelingen solche Kontextualisierungsleistungen Maschinen prinzipiell weniger gut. Die unter dem Stichwort des «semantic web» zusammengefassten Bemühungen begegnen dieser Schwierigkeit dadurch, dass sie nicht nur die Daten selbst (in einer allenfalls flachen Struktur) speichern, sondern vielmehr auch deren Bedeutung und das semantische Geflecht, in dem sie stehen, offenlegen und dem Datenmodell mit einzubeschreiben versuchen.
In den weiteren Kontext dieser Bemühungen einer semantischen Anreicherung der Daten gehören auch die seit den 90er Jahren in der Informatik verstärkt geführten Diskussionen um Ontologien. Implizit spielten ontologische Überlegungen beim Entwurf von Datenbanken und der zugehörigen Datenmodelle freilich schon lange eine Rolle. In jedem Datenmodell stecken unausgesprochene Annahmen über den Aufbau und die Struktur jenes Teils der Welt, über den man in der Datenbank Informationen speichern will. Durch die Festlegung, welche Tabellen mit welchen Spalten angelegt werden und wie das Geflecht ihrer Beziehungen ausgestaltet wird, trifft der konzeptionelle Schöpfer der Datenbank gleichzeitig Entscheidungen darüber, welche Arten von Objekten mit welchen Eigenschaften und Beziehungen er in dem betrachteten Gegenstandsbereich als wesentlich ansieht und welche anderen Aspekte der Wirklichkeit er demgegenüber für nebensächlich hält und damit aus der Modellierung ausklammert.
Diese implizite Vorstrukturierung der Wirklichkeit durch das Datenmodell tritt allerdings meist erst dann ins Bewusstsein, wenn man sich vor die Aufgabe gestellt sieht, die Daten von zwei Datenbanken interoperabel zu machen, denen gänzlich verschiedene Datenmodelle und damit grundverschiedene Sichten auf den Gegenstandsbereich zugrunde liegen. Die beiden unterschiedlichen Perspektiven können letztlich nur durch eine dritte, höherstufige Sicht überwunden werden, d.h. durch eine Ontologie, die ebenfalls ein konzeptuelles Modell der Wirklichkeit darstellt, welches aber so allgemein und gleichzeitig semantisch reichhaltig aufgebaut ist, dass andere, spezifischere Datenmodelle jederzeit auf dasselbe abgebildet werden können.
Ontologien spielen indes nicht nur als Referenz-Modelle, die als Brücke für ansonsten unvereinbare Datenmodelle fungieren, eine wichtige Rolle, sondern können auch den Entwurf neuer Datenmodelle kreativ anleiten. Ein Datenmodell, das auf einer solchen allgemeinen Sicht der Wirklichkeit beruht, erweist sich als sehr robust und flexibel, so dass auch der Import neuer Daten mit einer anderen Struktur keine unlösbaren Probleme aufwerfen sollte, die nur durch nachträgliche, meist relativ teure Veränderungen des Datenmodells gelöst werden können.
Doch wie muss eine Ontologie aufgebaut sein, um diese Anforderungen zu erfüllen? CIDOC-CRM, um eine sehr bekannte Ontologie herauszugreifen, löst dieses Problem durch eine hierarchische Struktur von Begriffen, an deren Spitze Konzepte stehen, die so allgemein gefasst sind, dass unter diese jede nur denkbare Entität subsumiert werden kann. Zunächst betrachtet CIDOC-CRM alles als Entität, um sogleich grundlegend zu unterscheiden zwischen jenen Dingen, die während ihrer ganzen Lebenszeit eine feststehende Identität bewahren (wie Personen, aber auch physikalische Objekte oder rein geistige Produkte wie Konzepte, Theorien, etc.), und jenen Entitäten, denen vornehmlich Ereignischarakter zukommt und die in einem direkten Bezug zu Raum und Zeit stehen und unwiederholbar in der Zeit vergehen.

Abbildung 1: CIDOC-CRM Top-level Klassen
Das durch diese allgemeinsten Konzepte aufgespannte begriffliche Grundgerüst wird im Zuge der CIDOC-CRM-Ontologie nicht nur immer weiter unterteilt, sondern kann vom Benutzer durch nahezu unbeschränkte eigene Differenzierungen beliebig erweitert und ausgebaut werden. In dieses Grundgerüst fügt CIDOC-CRM darüber hinaus eine beträchtliche Zahl von grundlegenden Relationen ein, mittels deren die Beziehungen zwischen den Entitäten zum Ausdruck gebracht werden.
Die Stärken des ontologischen Ansatzes zeigen sich vor allem dort, wo durch den vorgeprägten konzeptuellen Rahmen frühzeitig die Komplexität mancher scheinbar einfachen Informationen sichtbar wird: So könnte man versucht sein, die Zeit von historischen Ereignissen durch ein einfaches Zeit- und Datumsfeld anzugeben. Für Ereignisse, die sich über eine bestimmte Zeitspanne erstrecken, würde man wohl bald zusätzlich ein zweites Zeit- und Datumsfeld einführen, so dass man sowohl den Start- als auch den Endpunkt bezeichnen könnte. Aber wie steht es mit anderen, komplexeren Ereignisformen (z.B. gesellschaftlichen Prozessen und Transformationen), deren Anfang und Ende nicht exakt bezeichnet werden können? Ausserdem ist bei historischen Ereignissen je nach Quellenlage mit unterschiedlichen Formen partiellen Wissens und Unwissens zu rechnen: So kann man vielleicht nur feststellen, dass ein Ereignis an einem bestimmten Tag bereits im Gange war, ohne ausschliessen zu können, dass es bereits weit früher begonnen hat. Die CIDOC-CRM-Ontologie, die oft auch als ereigniszentriert bezeichnet wird, verfügt gerade im Bereich der temporalen Bestimmung über ein reichhaltiges Geflecht von Beziehungen, die eine semantisch flache Repräsentation von Zeitangaben im Prinzip von vornherein verhindern.
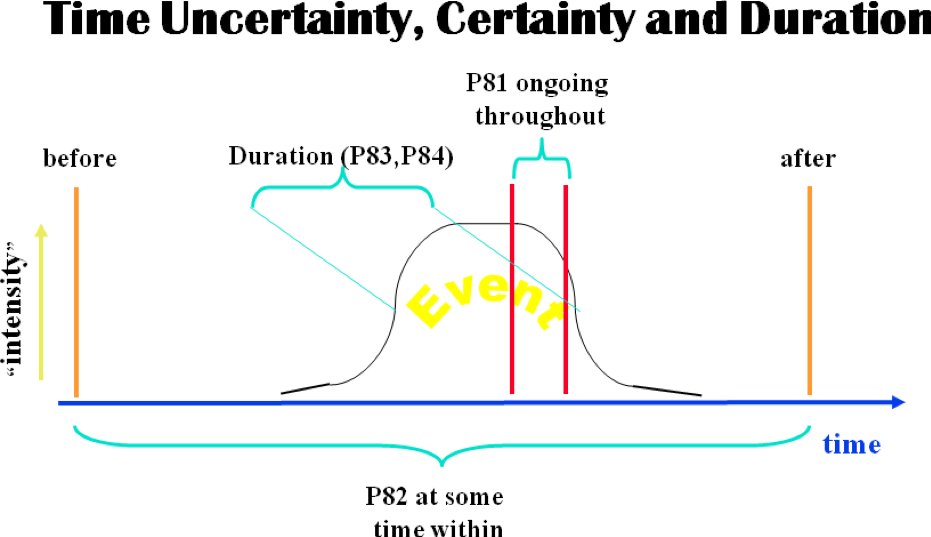
Abbildung 2: Temporale Bestimmungen in CIDOC-CRM
Diese hier skizzenhaft vorgetragenen Vorteile eines ontologisch abgesicherten Datenmodells haben uns letztlich auch dazu bewogen, beim Entwurf der Struktur der histHub-Datenbanken auf die CIDOC-CRM-Ontologie abzustellen.
Autor: Marc Zobrist