HistHub befasst sich in einer Blogserie mit der Aufbereitung und Anreicherung von Daten in OpenRefine. Dieser Beitrag beschäftigt sich mit Clustern als Methode zum Reinigen von Daten und mit den verschiedenen Methoden, die OpenRefine dafür bietet.
Die Beispiele und Screenshots in diesem Beitrag stammen wieder aus dem Projekt mit den Metadaten zu den Fotografien von Annemarie Schwarzenbach. Die Arbeitsschritte können mit einem anderen Datensatz (oder über andere Spalten dieses Datensatzes) nachvollzogen werden.
Cluster sind Vorschläge des Computers, welche Einträge in einer Spalte das gleiche meinen könnten. Bei den Facetten wird jeweils das Vorkommen des exakt gleichen Eintrags gezählt. Schon ein kleiner Unterschied wie ein Leerschlag macht aus eigentlich identischen Einträgen verschiedene. Mit Clustern ist die Korrektur solcher Fehler ganz einfach. histHub zeigt wie.
Es gibt zwei Möglichkeiten, Cluster aufzurufen:
- Eine Text-Facette für die zu bearbeitende Spalte aufrufen (Spaltenmenü -> «Facet» -> «Text facet»), dann in der Facetten-Anzeige oben rechts den Button «Cluster» anwählen.
- über das Spaltenmenü -> «Edit cells» -> «Cluster and edit…».
Beide Wege führen zum gleichen Ziel:
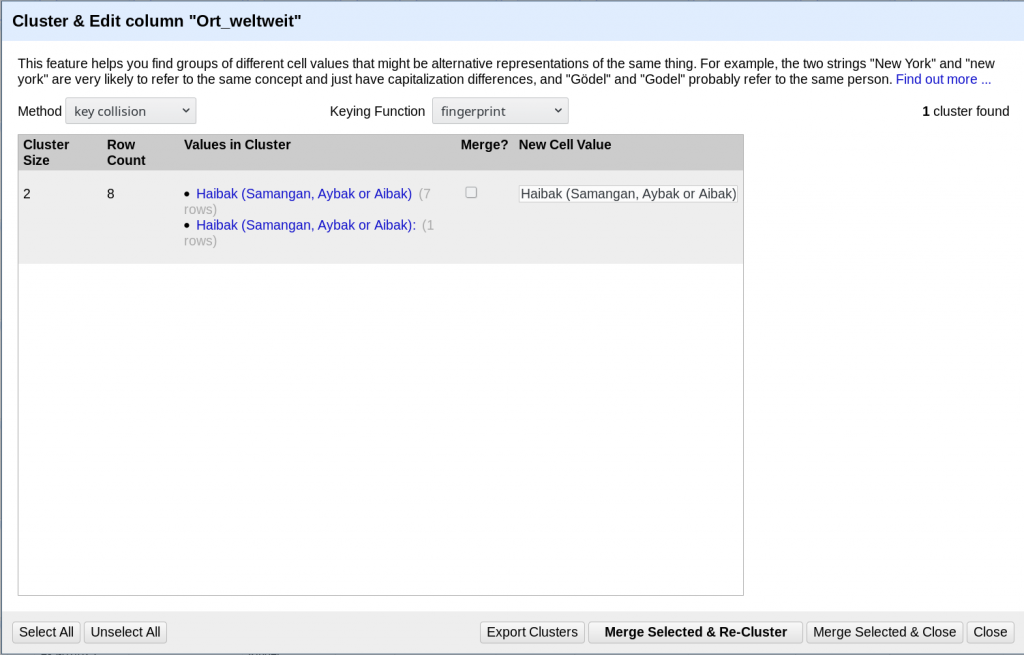
OpenRefine hat hier mit einem Algorithmus nach ähnlichen Einträgen gesucht. In diesem Beispiel sind die Einträge bis auf einen Doppelpunkt gleich. In der Spalte «Merge?» kann nun ein Haken gesetzt werden, wenn die Einträge vereinheitlicht werden sollen. In der Spalte «New Cell Value» schlägt OpenRefine vor, wie der vereinheitlichte Inhalt aussehen soll. Alle Einträge werden mit diesem Text ersetzt.
Diese Vorschläge richten sich, je nach gewähltem Algorithmus danach,
- welche Ausprägung des vermutlich gleichen Werts zuerst vorkommt.
- welche Ausprägung des vermutlich gleichen Werts häufiger vorkommt.
Es muss also immer kontrolliert werden, ob hier der gewünschte Wert eingegeben wurde.
Unten links können bequem alle Vorschläge ausgewählt oder die Auswahl aufgehoben werden. «Export Clusters» ermöglicht den Export als JSON. «Merge Selected & Re-Cluster» vereinheitlicht die ausgewählten Einträge und erstellt neue Cluster. Danach kann mit anderen Algorithmen (siehe unten) nach weiteren Vorschlägen gesucht werden. «Merge Selected & Close» vereinheitlicht die ausgewählten Einträge und schliesst das Cluster-Fenster. «Close» bricht die Aktion ab.
Clustervorschläge können nur als Ganzes angenommen oder abgelehnt werden. Wenn also von vier Einträgen in einem Cluster drei zusammengehören, der Vierte jedoch eigenständig bleiben soll, muss der Cluster abgelehnt werden. Ein anderer Algorithmus liefert möglicherweise das gewünschte Ergebnis, ansonsten muss von Hand nachgebessert werden.
Der Link «Browse this Cluster» erscheint bei Mouseover. Damit lassen sich alle Zeilen in einem vorgeschlagenen Cluster ansehen und bei Bedarf von Hand vereinheitlichen.
Erkennt OpenRefine mehrere Cluster, bietet es mit Facetten die Möglichkeit zur Einschränkung.
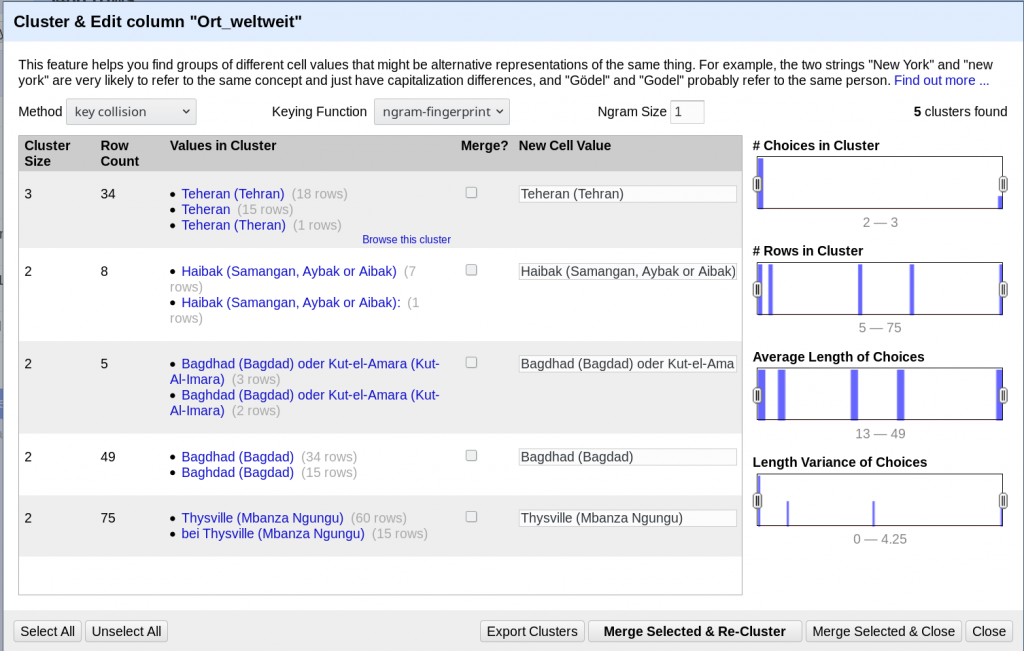
So können beispielsweise zuerst die Cluster bearbeitet werden, die mehr als 40 Zeilen in der Tabelle betreffen, oder die eine bestimmte Zeichenanzahl nicht über- oder unterschreiten.
Ein sinnvolles Vorgehen ist es, die verschiedenen Cluster-Methoden einfach durchzuprobieren, ein vertieftes Verständnis der dahinterstehenden Mechanismen ist nicht zwingend nötig. Ein Überblick über die Eigenheiten der Cluster-Methoden ist aber sinnvoll, da so gezielt die passende Methode für die vorliegenden Daten gewählt werden kann. Die Reihenfolge der Methoden orientiert sich daran, wie exakt die Übereinstimmung für einen Clustervorschlag sein muss.
Key collision
Unter diesem Begriff werden Clustermethoden gesammelt, die nach dem wesentlichen Teil («key») des Werts suchen. Stimmt dieser überein, schlägt die Methode Cluster vor.
Key collision Methoden brauchen wenig Zeit für die Berechnung, auch wenn grosse Datensätze bearbeitet werden.
fingerprint
FIngerprint ist die Standardmethode, weil sie wenige falsche Treffer vorschlägt. Sie entfernt Leerzeichen und Satzzeichen, betrachtet alle Buchstaben als Kleinbuchstaben und ignoriert Umlaute. Einzelne Worte werden auseinandergenommen. Da Satzzeichen ignoriert werden, fügt die Methode also beispielsweise «Schwarzenbach, Annemarie» und «Annemarie Schwarzenbach» in einem Cluster zusammen.
Die Methode ist nicht ideal für Datensätze mit vielen Umlauten, weil sie diese ignoriert.
ngram-fingerprint
Diese Methode funktioniert ähnlich, wird aber durch ein N-Gramm ergänzt. Dadurch werden auch Cluster erkannt, wenn innerhalb des Strings, also der Zeichenkette, Buchstaben vertauscht sind.
Die Grösse des N-Gramms kann gewählt werden. Ein grosser Wert hat keine Vorteile gegenüber der Standard-fingerprint-Methode. Ein 2-Gramm oder 1-Gramm hingegen wird einige falsche Vorschläge, aber auch neue Matches hervorbringen.
Beispielsweise findet ein normaler fingerprint keine Übereinstimmung zwischen «Teheran» und «Tehran». Ein ngram-fingerprint mit dem Wert 1 clustert die Einträge zusammen.
metaphone-3
Diese Methode basiert auf einem phonetischen fingerprint. Metaphone-3 ist spezifisch auf die englische Aussprache zugeschnitten, ist also vor allem bei englischsprachigen Datensätzen anzuwenden.
cologne-phonetic
Wie metaphone-3 ist cologne-phonetic eine phonetische fingerprint Methode. Cologne-phonetic ist auf die deutsche Sprache ausgelegt.
Die phonetischen Methoden helfen, Schreibfehler oder Ungleichheiten aufgrund verschiedenener Rechtschreibungen aufzuspüren.
nearest neighbour
Die bisher beschriebenen Methoden brauchen kaum Berechnungszeit. Oft sind sie aber entweder zu eng oder zu locker, so dass es viele falsche Cluster gibt, aber auch Einträge nicht zusammen geclustert werden, obwohl sie zusammengehören.
Präziser sind Methoden, die nach der Nächste-Nachbarn-Klassifikation funktionieren. Strings werden verglichen, und wenn die Abweichung einen bestimmten Grenzwert nicht überschreitet, wird ein Cluster vorgeschlagen.
Der Nachteil daran ist, dass es schon für kleine Datenmengen sehr viele Berechnungen braucht, was die Methode langsam macht. OpenRefine schaltet deshalb eine key collision davor, die Blöcke mit ähnlichen Einträgen schafft. Es ist möglich, die Grösse der Blöcke im Feld «Block» zu bestimmen, wenn eine «Nearest-neighbour»-Methode gewählt wurde. Werte unter drei verlangsamen die Berechnung und bringen selten bessere Ergebnisse.
Der Unterschied zwischen den nearest neighbour Methoden liegt in der Art der Berechnung der Differenz zwischen zwei Strings.
levensthein
Auch Bearbeitungs-Distanz genannt, berechnet diese Methode die Anzahl Bearbeitungsschritte zwischen zwei strings. «Teheran» und «Tehran» ist einen Arbeitsschritt entfernt (einen Buchstaben einfügen), «Buenos Aires» und «Buenosaires» zwei.
In OpenRefine kann die Distanz im Feld «Radius» eingestellt werden. Grosse Zahlen liefern hier, vor allem bei kurzen Zeichenketten, übermässig viele Treffer.
PPM
Diese Methode baut auf der Kompression von Textstrings auf. Eine solche Kompression berechnet den Inhalt eines Strings. Entsprechend muss der Inhalt von Zelle A ungefähr dem Inhalt von A+B entsprechen.
Diese Methode gibt sehr viele Treffer zurück. Deshalb sollte sie erst nach den anderen Cluster-Methoden genutzt werden. Ausserdem ist sie für längere Einträge pro Zelle präziser als für kürzere.
Mehr Informationen zum Clustern
OpenRefine selbst hat auf Github ausführliche Erläuterungen zu den Clustermethoden publiziert, die auch als Grundlage für diesen Artikel dienen.
Fragen, Anregungen oder Wünsche zu OpenRefine oder zu histHub nehmen wir gerne per Mail entgegen.