In einer Blogserie befasst sich histHub mit der Aufbereitung und Anreicherung von Daten in OpenRefine. Dieser Beitrag beleuchtet das Deduplizieren, also das finden und löschen doppelter Einträge.
Kriterien zum Deduplizieren
Voraussetzung dafür ist (mindestens) eine Spalte, in der Dubletten eindeutig als solche auftauchen. In den Metadaten zu den Fotografien von Annemarie Schwarzenbach gibt es zwei Signatur-Spalten. Beide diese Spalten enthalten einzigartige Signaturen für jede einzelne Zeile. Richtige Dubletten enthält dieser Datensatz nicht.
Zu Übungszwecken können wir nun beispielsweise anhand der Spalte Titel_Name deduplizieren, sodass jeweils nur ein Eintrag pro identischen Titel übrigbleibt.
Die Methode zum Entfernen von Dubletten, die wir gleich zeigen werden, übernimmt jeweils den ersten vorkommenden Eintrag und entfernt alle anderen.
Vorgehen
OpenRefine bietet keinen einfachen «Deduplizieren»-Knopf. Die Sortier-Funktion und die «Blank-Down»-Funktion werden in Kombination mit einer Facette zum Ziel führen. Doch der Reihe nach.
Sortieren
Nachdem wir entschieden haben, anhand welcher Spalte dedupliziert werden soll, sortieren wir alle Einträge in dieser Spalte. Dazu zuerst «Sort» wählen,
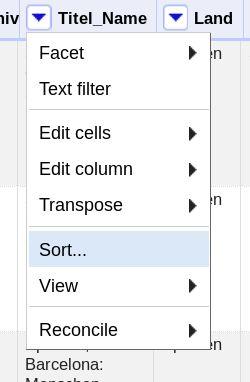
und im sich darauf öffnenden Fenster auf «OK» klicken:
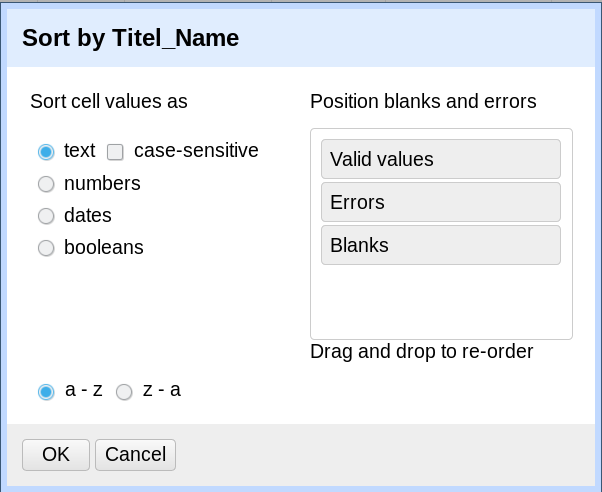
Dies sortiert die Zeilen alphabetisch. Die Sortierung ist jedoch noch nicht permanent. In der Spalte «All», in der OpenRefine jeder Zeile selbst einen Identifier gibt, haben alle Zeilen ihren ursprünglichen Identifier behalten. Und nach dieser Spalte richtet sich die Sortierung, von der OpenRefine ausgeht. Die Sortierung permanent zu machen benötigt nur wenige Klicks.
In der Kopfzeile gibt es neu neben den Schaltflächen zur Auswahl der Anzahl sichtbarer Zeilen den Butten «Sort». Ein Klick darauf öffnet ein Dropdown-Menü, aus dem wir «Reorder rows permanently» wählen.

Die Identifier in der Spalte «All» beginnen jetzt wieder bei 1, das heisst alle Zeilen haben einen neuen Identifier von OpenRefine erhalten. Erst jetzt ist die Sortierung eine Transformation an den Daten, die auch im Undo/Redo Tab rückgängig gemacht werden kann.
Blank down
Die Funktion «Blank down» ist im Standardrepertoire von OpenRefine. Sie entfernt den Inhalt aller aufeinanderfolgenden identischen Einträge, wobei sie den ersten beibehält. Zu finden ist die Funktion unter «Edit cells» –> «Blank down»:
Wie immer zeigt OpenRefine an, wie viele Zeilen bearbeitet wurden.
Facettieren
Die «doppelten» Einträge sind nun dadurch markiert, dass sie in der Spalte «Titel_Name» keinen Inhalt haben. Zeilen mit leeren Zellen in einer Spalte lassen sich ganz leicht per Facette herausgreifen.
In der Facettenauswahl muss nun «true» gewählt werden. Bei der Betrachtung der Facette wird deutlich, dass es in dem Datensatz bei fast 3500 Einträgen 950 unterschiedliche Titel gibt. So viele Zeilen werden nach dem Deduplizieren übrigbleiben. (Keine Sorge, die Schritte lassen sich ganz leicht rückgängig machen).
Entfernen
Das Entfernen von Zeilen wird über die Spalte «All» aufgerufen.

Übrig bleiben «0 matching rows», da eine Facette aktiv ist. Diese kann nun einfach entfernt werden.
Rückgängig machen
Das Deduplizieren ist zwar ein relativ aufwändiger Ablauf, für OpenRefine sind es jedoch nur drei Schritte. Sichtbar wird das, wenn wir auf «Undo/Redo» gehen.

Hier lassen sich diese Arbeitsschritte nachvollziehen und rückgängig machen.
Fragen, Anregungen oder Wünsche zu OpenRefine oder zu histHub nehmen wir gerne per Mail entgegen.